

推测系统是由输入、推测和输出三部分组成,这个架构即是冯·诺依曼架构,很是的直爽。面前行业内有许多堪称突破冯·诺依曼架构的系统处女膜 在线av,但背后逻辑齐是驯顺冯·诺依曼架构的指导想想,严格来说不存在突破的说法。

然后是摩尔定律。基于CPU的摩尔定律确凿依然到了极限,天然说咱们面前晶体管的晋升亦然轻松到了一个极限,然则要是咱们把摩尔定律动作念一个KPI的话,那么对行业来说它又是一个很是难题的门道图,各人需要抓续不停地晋升性能,是以说关于推测性能的追求其实是永无绝顶的。
另外,再直爽先容下软件和硬件。当先,提示是软件和硬件之间的引子,那么提示的复杂度决定了这个软硬件的解耦经过。ISA(提示集架构)之下,CPU、GPU等万般处分器是硬件;ISA之上,万般方法、数据集、文献等是软件。

按照提示的复杂度,典型的处分器平台梗概分为CPU、协处分器、GPU、FPGA、DSA、ASIC。从左往右,单元推测越来越复杂,性能越来越好,而纯真性越来越低。任务在CPU驱动,则界说为软件驱动;任务在协处分器、GPU、FPGA、DSA或ASIC驱动,则界说为硬件加快驱动。
什么是超异构推测?
那么下一步,咱们认为是抓续往前走向超异构,为什么这件事情大要存在?
咱们认为有几个原因使得超异组成为可能。那么当先极少即是超大限度的推测集群,其次是复杂宏系统,是由分层分块的组件(系统)组成。单就业器的宏系统复杂度,以及超大限度的云和边际推测,使得“二八定律”在系统中大宗存在:把相对详情的任务千里淀到基础设施层,相对弹性的千里淀到弹性加快部分,其他赓续放在CPU(CPU兜底)。
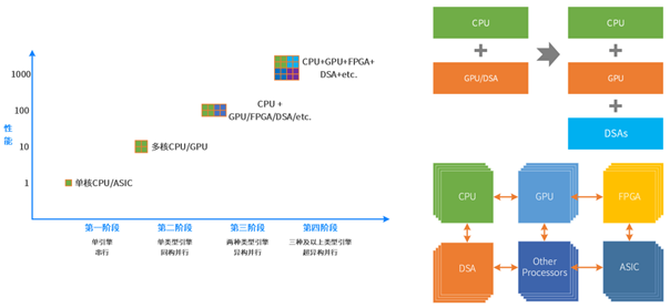
把更多的异构推测整合重构,万般型处分器间充分的、纯确凿数据交互,酿成超异构推测。异日就会有三个和三个以上类型的处分引擎,共同组成超异构并行。
接下来咱们先容一些案例,当先是英特尔建议的超异构相关办法。当它建议来之后,并莫得给出来齐全的一个家具,反而是在超异构办法左近作念了许多职责,最终我以为会有很齐全的东西出来。
2019年,英特尔建议超异构推测相关办法:XPU是架构组合,包括CPU、GPU、FPGA 和其他加快器;OneAPI是开源的跨平台编程框架,底层是不同的XPU处分器,通过OneAPI提供一致性编程接口,使得期骗跨平台复用。
即是说我任何一个期骗,我既不错在CPU驱动,又不错在GPU驱动,又不错在专用的ASIC上驱动,通过OneAPI就不错跨不同的处分器平台,婷儿 勾引就不错自稳妥的去在平台上也有不同的推测资源。再说说英特尔的IPU,英特尔IPU跟面前市面上相比火爆的DPU是一个办法。

咱们对英特尔的超异构推测进行一个回来,那它有CPU、GPU、FGPA,以及DSA和ASIC所组成的IPU,况兼有了这个跨平台,也即是它所谓的XPU战术和oneAPI框架,最终把它整合成一个大芯片。
咱们再来看英伟达Thor,这里很要道,为什么是数据中心架构?它所使用CPU、GPU、DPU跟数据中心内部用的架构一模相同,辞别只是在于规格的不同,譬如说数据中心可能有50个核,在末端可能用到30个核。
超等末端与传统末端最大的辞别在于:支抓臆造化,支抓多系统驱动,支抓微就业。手机、平板、个东说念主电脑等传统AP是一个系统:部署好OS,上头驱动万般期骗,软件附属于硬件而存在。自动驾驶等超等末端,需要通过臆造化将硬件切分红不同规格,供不同形态的多个系统驱动,况兼各个系统之间需要作念到环境、期骗、数据、性能、故障、安全等方面的难题。
再然后看一下英伟达在数据中心的布局,NVIDIA Grace Hopper超等芯片是CPU+GPU,NVIDIA筹划从Bluefield DPU四代起,把DPU和GPU两者集成单芯片。Chiplet时间逐渐锻真金不怕火,异日趋势是CPU+GPU+DPU的超异构芯片。
为什么不言而喻?这内部有英伟达我方的一个说法,我把这个进行了一个回来。当先,推测和网罗不停交融:推测面对许多挑战,需要网罗的协同;网罗拓荒亦然推测机,加入推测集群,成为推测的一部分。

数据在网罗中流动,推测节点依靠数据流动来驱动推测。系数系统的内容是数据处分,那么系数的拓荒就齐是DPU。以DPU为基础,不停交融CPU和GPU的功能,DPU会逐渐演化成数据中心协调的超异构处分器。

咱们再来看高通。高通在手机端是很猛烈的存在,往汽车域罢休上发展也会有先天上风,但要是以最终的超等单芯片来讲,相关于英伟达如故有点颓势的。
趋势一:ARM成为万般性推测的难题选拔
跟着自动驾驶、云游戏、VR/AR等期骗的兴起,以及物联网、移动期骗、短视频、个东说念主文娱、东说念主工智能的爆炸式增长,期骗越来越万般化;期骗的万般化驱动算力万般性发展。海量万般性的算力需求,加快了算力步地调度,ARM算力从镶嵌式场景快速蔓延至就业器场景。同期,在中国,就业器侧ARM生态已渐渐锻真金不怕火,并全面期骗于民生国计行业。建议企业基于业务需求,识别适合ARM架构的业务场景,主动权术部署ARM架构就业器;有节拍地开展现存期骗适配、迁徙,并基于ARM架构,抓续开发原生期骗;通过全栈软硬件优化,充分开释万般算力,施展极致性能。
趋势二:数字化走向长远,操作系统走向万般性算力和全场景的协同
操作系统作为推测产业中最基础的软件,承担着轮廓底层硬件,进取层期骗提供协调接口的中枢功能,是推测产业的要道方法。面向万般性推测和海量期骗场景,操作系统应支抓万般算力和多种期骗的协同,成为数字产业的可靠软件底座。建议权术部署支抓数字基础设施万般算力的操作系统,使能全场景期骗协同立异;分析期骗迁徙策略,制定期骗迁徙筹划,完成期骗高效迁徙;加入开源操作系统社区,积极拥抱开源、回馈开源。
趋势三:数字经济发展激发算力需求爆炸式增长,东说念主工智能算力增长是主要增量
现时,数字经济正在成为全球经济的主要增长点,算力作为数字经济时期新的坐褥力,是撑抓数字经济发展的坚实基础,其中东说念主工智能算力需求一直是指数级增长。同期,东说念主工智能正日益快速渗入行业期骗的中枢场景。建议产业加快AI基础设施拓荒,让AI算力成为像水和电相同的各人资源;加快东说念主工智能投入行业要道场景,使能行业智能化升级;产学研联袂,共筑东说念主工智能产业生态。
趋势四:大模子成为AI限度期骗难题途径,科学推测正在投入科学智能新阶段
现时东说念主工智能界限,“大算力+大数据”正在催生大模子的快速发展,孵化系列行业新期骗。而科学推测是继大模子之后,AI发展的另一难题场所,科学推测正在从传统HPC投入科学智能新阶段。建议产学研各界集聚大模子发展因素,使能大模子从权术到落地;打造科学智能基础平台、联袂构筑科学智能生态,加快产业闭环。
趋势五:绿色高效成为算力基础设施拓荒的要道诉求
在双碳筹划下,算力基础设施的拓荒愈加刺目能耗,需要通过从单界限立异走向系统级立异,收场绿色高效。建议拓荒模式从传统的部件堆叠渐渐走向集群全栈一体化;散热形貌渐渐从传统风冷走向风液搀杂或全液冷;算力评估渐渐从面向硬件的裸算力,走向面向业务的灵验算力。
趋势六:算力网罗将成为难题的算力供给形貌
在“东数西算”“网罗强国”等战术的牵引下,以东说念主工智能推测中心、超算中心、一体化大数据中心等为代表的算力基础设施,成为国度新基建的难题组成,算力拓荒从散播化走向集约化。跟着各地算力中心/算力基础设施赓续建成后,东说念主工智能算力从算力中心,走向算力网罗。建议各地加快算力基础设施拓荒;积极加入中国算力网,收场算力集聚分享。
预测处女膜 在线av,到2030年,全球通用算蓄意力相 比2020年将增长10倍,AI算力将增长500倍。推测从通用推测投入通用推测+AI推测的万般性推测时期。